40. 高级几何构造¶
nyc_subway_stations 图层目前为止为我们提供了很多有趣的例子,但它有一个显著的问题
虽然它是一个包含所有站点的数据库,但它不容易实现路线的可视化!在本章中,我们将使用 PostgreSQL 和 PostGIS 的高级功能,从地铁站点的点图层构建一个新的线性路线图层。
我们的任务尤其困难,因为存在两个问题
nyc_subway_stations的routes列在每行中都有多个路线标识符,因此可能出现在多个路线中的站点在表中只出现一次。与前一个问题相关,站点表中没有路线排序信息,因此虽然可以找到特定路线中的所有站点,但无法使用属性确定列车通过这些站点的顺序。
第二个问题更难:给定路线中一组无序的点,我们如何对它们进行排序以匹配实际路线。
以下是 ‘Q’ 列车的停靠站
SELECT s.gid, s.geom
FROM nyc_subway_stations s
WHERE (strpos(s.routes, 'Q') <> 0);
在此图中,停靠站用其唯一的 gid 主键标记。
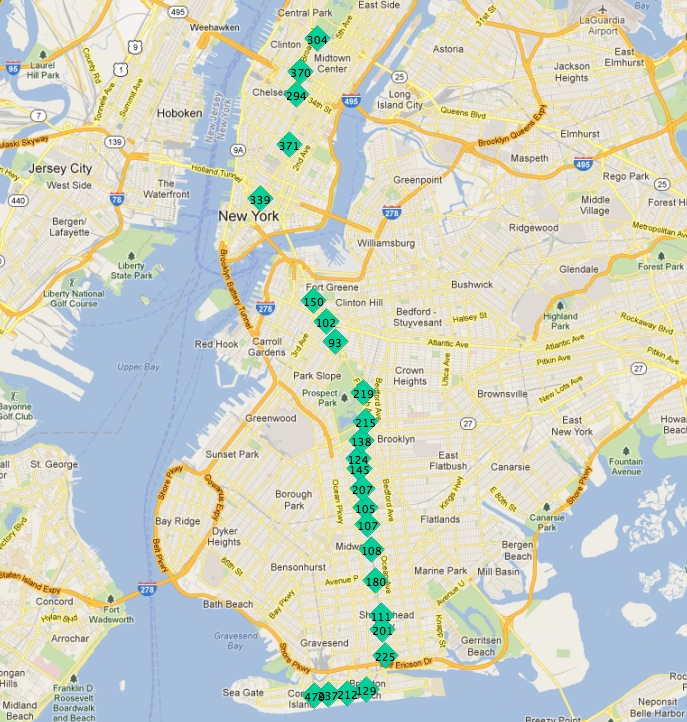
如果我们从其中一个终点站开始,线路上的下一个站点似乎始终是最近的。我们可以重复这个过程,每次都将之前找到的所有站点从搜索中排除。
在数据库中运行这种迭代例程有两种方法
公共表表达式 (CTE) 的优点是不需要定义函数即可运行。以下是计算 ‘Q’ 列车路线线的 CTE,从最北端的站点(其中 gid 为 304)开始。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT geom, idlist FROM next_stop;
CTE 由两个部分组成,并合并在一起
第一部分为表达式建立一个起点。我们获取初始几何图形并初始化已访问标识符的数组,使用 “gid” 304(线路末端)的记录。
第二部分迭代直到找不到更多记录。每次迭代时,它通过对 “next_stop” 的自引用获取上一次迭代的值。我们搜索 Q 线上的每个站点 (strpos(s.routes,'Q')),这些站点我们尚未添加到访问列表中 (NOT n.idlist @> ARRAY[s.gid]),并按其与前一个点的距离排序,仅取第一个(最近的)。
除了递归 CTE 本身之外,这里还使用了许多高级 PostgreSQL 数组功能
我们正在使用 ARRAY!PostgreSQL 支持任何类型的数组。在本例中,我们有一个整数数组,但我们也可以构建一个几何图形数组或任何其他 PostgreSQL 类型。
我们正在使用 array_append 来构建已访问标识符的数组。
我们正在使用 @> 数组运算符(“数组包含”)来查找我们已访问过的 Q 列车站。@> 运算符要求两侧都有 ARRAY 值,因此我们必须使用 ARRAY[] 语法将单个 “gid” 数字转换为单条目数组。
当您运行查询时,您将按找到的顺序(即路线顺序)获取每个几何图形,以及已访问标识符的列表。将几何图形包装到 PostGIS ST_MakeLine 聚合函数中会将几何图形集转换为单个线性输出,该输出按提供的顺序构建。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom FROM next_stop;
看起来像这样
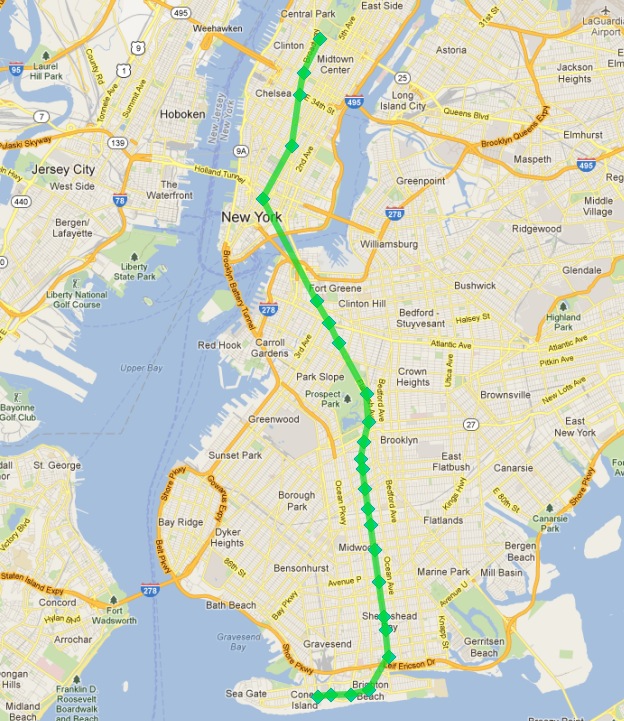
成功!
除了两个问题
我们这里只计算了一条地铁路线,我们想计算所有路线。
我们的查询包括一个先验知识,即作为构建路线的搜索算法的种子的初始站点标识符。
让我们首先解决难题,找出路线上的第一个站点,而无需手动查看构成路线的站点集。
我们的 ‘Q’ 列车停靠站可以作为起点。路线的终点站有什么特征?
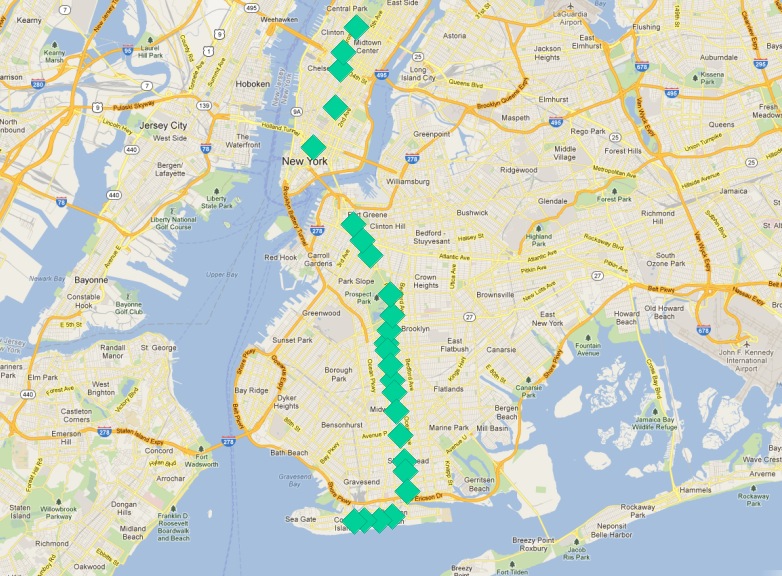
一种答案是“它们是最北和最南的站点”。但是,想象一下,如果 ‘Q’ 列车从东向西行驶。该条件仍然成立吗?
终点站的一种不太具方向性的特征是“它们是距离路线中间最远的站点”。有了这个特征,路线是南北还是东西走向并不重要,重要的是它或多或少地朝一个方向运行,尤其是在末端。
由于没有 100% 的启发式方法来找出终点,让我们尝试一下第二个规则。
注意
“距离中间最远”规则的一个明显失败模式是环线,例如英国伦敦的环线。幸运的是,纽约没有这样的线路!
要找出每条路线的终点站,我们首先必须找出有哪些路线!我们找到不同的路线。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
)
SELECT * FROM routes;
请注意两个高级 PostgreSQL ARRAY 函数的使用
string_to_array 接收一个字符串,并使用分隔符字符将其拆分为数组。PostgreSQL 支持任何类型的数组,因此可以构建字符串数组,就像本例一样,但也可以构建几何图形和地理图形数组,我们将在本例后面看到。
unnest 接收一个数组,并为数组中的每个条目构建一个新行。其效果是将嵌入在单行中的“水平”数组转换为“垂直”数组,每个值对应一行。
结果是所有唯一地铁路线标识符的列表。
route
-------
1
2
3
4
5
6
7
A
B
C
D
E
F
G
J
L
M
N
Q
R
S
V
W
Z
(24 rows)
我们可以通过将此结果连接回 nyc_subway_stations 表来构建此结果,以创建一个新表,该表对于每个路线,都包含该路线上每个站点的行。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
)
SELECT * FROM stops;
gid | geom | route
-----+----------------------------------------------------+-------
2 | 010100002026690000CBE327F938CD21415EDBE1572D315141 | 1
3 | 010100002026690000C676635D10CD2141A0ECDB6975305141 | 1
20 | 010100002026690000AE59A3F82C132241D835BA14D1435141 | 1
22 | 0101000020266900003495A303D615224116DA56527D445141 | 1
...etc...
现在,我们可以通过将每条路线的所有站点收集到单个多点中,并计算该多点的质心来找到中心点。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
)
SELECT * FROM centers;
‘Q’ 列车停靠站集合的中心点如下所示
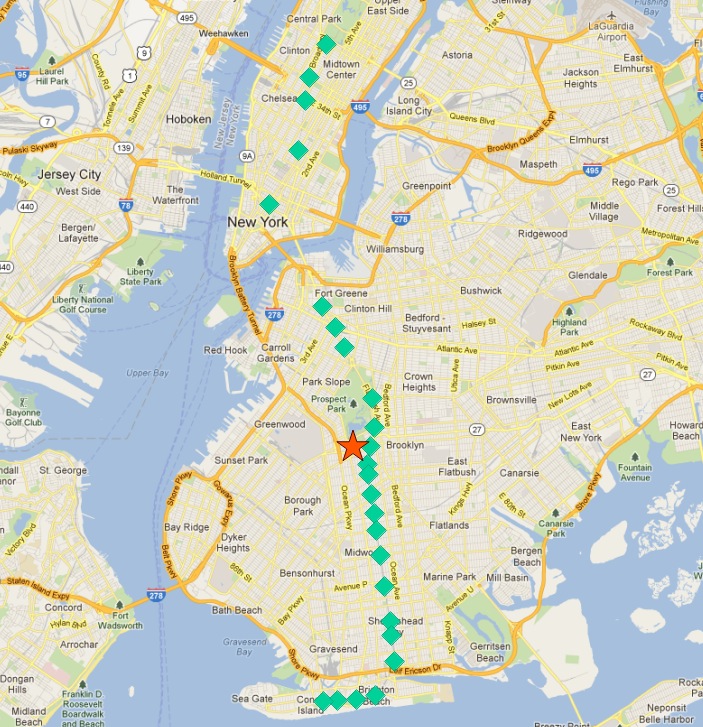
因此,最北端的站点,即终点,似乎也是距离中心最远的站点。让我们计算每条路线的最远点。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
SELECT * FROM first_stops;
这次我们添加了两个子查询
stops_distance 将中心点连接回站点表,并计算每条路线的站点和中心之间的距离。结果按顺序排列,以便记录以每条路线的批次形式出现,最远的站点作为批次的第一个记录。
first_stops 通过仅获取每个不同组的第一个记录来过滤 stops_distance 输出。由于我们对 stops_distance 进行排序的方式,第一个记录是最远的记录,这意味着它是我们要用作构建每条地铁路线的起始种子的站点。
现在我们知道每条路线,并且我们(大致)知道每条路线从哪个站点开始:我们已准备好生成路线线!
但首先,我们需要将递归 CTE 表达式转换为可以使用参数调用的函数。
CREATE OR REPLACE function walk_subway(integer, text) returns geometry AS
$$
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom AS geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = $1)
UNION ALL
(SELECT
s.geom AS geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, $2) != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom
FROM next_stop;
$$
language 'sql';
现在我们准备好了!
CREATE TABLE nyc_subway_lines AS
-- Distinct route identifiers!
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
-- Joined back to stops! Every route has all its stops!
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
-- Collects stops by routes and calculate centroid!
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
-- Calculate stop/center distance for each stop in each route.
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
-- Filter out just the furthest stop/center pairs.
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
-- Pass the route/stop information into the linear route generation function!
SELECT
ascii(route) AS gid, -- QGIS likes numeric primary keys
route,
walk_subway(gid, route) AS geom
FROM first_stops;
-- Do some housekeeping too
ALTER TABLE nyc_subway_lines ADD PRIMARY KEY (gid);
这是我们在 QGIS 中可视化的最终表的样子
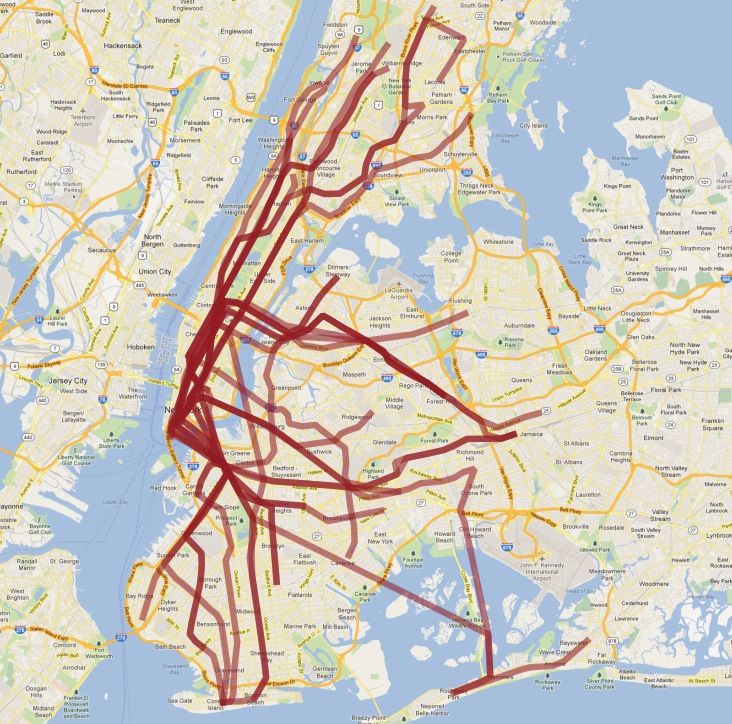
像往常一样,我们对数据的简单理解存在一些问题
实际上有两条 ‘S’(短距离“摆渡”)列车,一条在曼哈顿,另一条在洛克威,我们将它们连接在一起,因为它们都称为 ‘S’;
‘4’ 列车(以及其他一些列车)在一条线路的末端分成两个终点站,因此“跟随一条线路”的假设被打破,结果在末端有一个有趣的钩子。
希望此示例提供了结合 PostgreSQL 和 PostGIS 的高级功能可能进行的一些复杂数据操作的示例。
