38. PostgreSQL 备份和恢复¶
备份 PostgreSQL 数据库的方法有很多,您选择哪种方法很大程度上取决于您如何使用数据库。
对于相对静态的数据库,可以使用基本的 pg_dump/pg_restore 工具来定期创建数据快照。
对于频繁更改的数据,使用“在线备份”方案可以持续将更新存档到安全位置。
在线备份是为 高可用性 实现复制和备用系统的基础,特别是对于 PostgreSQL >= 9.0 的版本。
38.1. 规划您的数据¶
正如在PostgreSQL 架构中所讨论的那样,确保生产数据始终存储在单独的架构中是管理数据时非常重要的**最佳实践**。原因有二:
备份和恢复架构中的数据比单独管理要备份的表列表要简单得多。
将数据表保留在“public”架构之外可以更轻松地进行升级,正如在软件升级中所讨论的那样。
38.2. 基本备份和恢复¶
使用 pg_dump 实用程序可以轻松备份整个数据库。该实用程序是一个命令行工具,可以使用脚本轻松实现自动化,也可以通过 PgAdmin 实用程序中的 GUI 调用它。
要备份我们的 nyc 数据库,我们可以使用 GUI,只需右键单击要备份的数据库
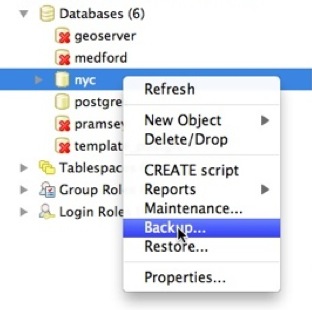
输入您要创建的备份文件的名称。
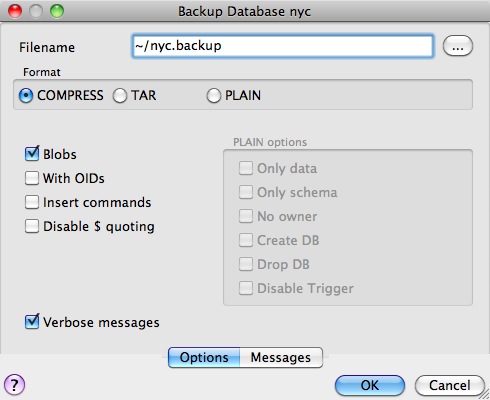
请注意,有三种备份格式选项:compress、tar 和 plain。
Plain 只是一个文本 SQL 文件。这是最简单的格式,并且在很多方面也是最灵活的,因为它可以轻松编辑或更改,然后重新加载到数据库中,从而允许离线更改所有权或其他全局信息。
Tar 使用 UNIX 存档格式将转储的组件保存在单独的文件中。使用 tar 格式允许 pg_restore 实用程序有选择地恢复转储的部分。
Compress 类似于 Tar 格式,但会单独压缩内部组件,允许有选择地恢复它们而无需解压缩整个存档。
我们将选中 Compress 选项并继续,保存备份文件。
可以使用如下命令行完成相同的操作
pg_dump --file=nyc.backup --format=c --port=54321 --username=postgres nyc
由于备份文件是压缩格式,我们可以使用 pg_restore 命令查看内容以列出清单。在 PgAdmin GUI 中,“View”是面板中的一个选项。
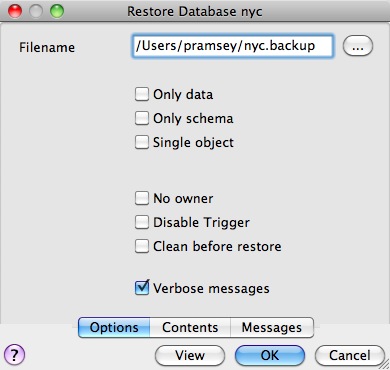
当您查看清单时,您可能会注意到其中有很多“FUNCTION”签名。
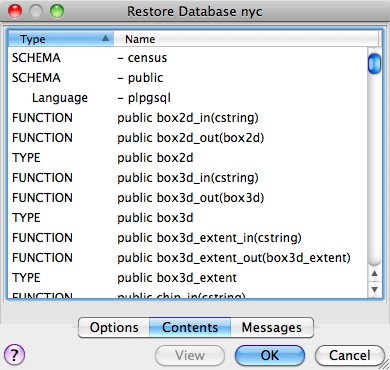
这是因为 pg_dump 实用程序会转储数据库中的**每个**非系统对象,其中包括 PostGIS 函数定义。
注意
PostgreSQL 9.1+ 包括一个“EXTENSION”功能,允许将 PostGIS 之类的附加包作为注册的系统组件安装,因此可以从 pg_dump 输出中排除。PostGIS 2.0 及更高版本支持使用此扩展系统进行安装。
我们可以使用 pg_restore 直接从命令行查看相同的清单
pg_restore --list nyc.backup
包含大量 PostGIS 函数签名的转储文件的问题在于,我们真正想要的是数据转储,而不是系统函数。
由于每个对象都在转储文件中,我们可以恢复到空白数据库并获得完整的功能。这样做时,我们希望我们恢复到的系统具有与我们转储的系统完全相同的 PostGIS 版本(因为函数签名定义引用了特定版本的 PostGIS 共享库)。
从命令行进行还原如下所示
createdb --port 54321 nyc2
pg_restore --dbname=nyc2 --port 54321 --username=postgres nyc.backup
仅转储数据而不包含函数签名,这是在架构中存储数据方便之处,因为有一个命令行标志可以仅转储特定架构
pg_dump --port=54321 -format=c --schema=census --file=census.backup
现在,当我们列出转储的内容时,我们只看到我们想要的数据表
pg_restore --list census.backup
;
; Archive created at Thu Aug 9 11:02:49 2012
; dbname: nyc
; TOC Entries: 11
; Compression: -1
; Dump Version: 1.11-0
; Format: CUSTOM
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 8.4.9
; Dumped by pg_dump version: 8.4.9
;
;
; Selected TOC Entries:
;
6; 2615 20091 SCHEMA - census postgres
146; 1259 19845 TABLE census nyc_census_blocks postgres
145; 1259 19843 SEQUENCE census nyc_census_blocks_gid_seq postgres
2691; 0 0 SEQUENCE OWNED BY census nyc_census_blocks_gid_seq postgres
2692; 0 0 SEQUENCE SET census nyc_census_blocks_gid_seq postgres
2681; 2604 19848 DEFAULT census gid postgres
2688; 0 19845 TABLE DATA census nyc_census_blocks postgres
2686; 2606 19853 CONSTRAINT census nyc_census_blocks_pkey postgres
2687; 1259 20078 INDEX census nyc_census_blocks_geom_gist postgres
只有数据表很方便,因为它意味着我们可以存储到安装了任何版本的 PostGIS 的数据库中,正如我们在软件升级中所讨论的那样。
38.2.1. 备份用户¶
pg_dump 实用程序一次操作一个数据库(如果您限制它,则一次操作一个架构或表)。但是,有关用户的信息存储在整个集群中,而不是存储在任何一个数据库中!
要备份您的用户信息,请使用 pg_dumpall 实用程序,并带有“–globals-only”标志。
pg_dumpall --globals-only --port 54321
您也可以使用默认模式的 pg_dumpall 来备份整个集群,但请注意,与 pg_dump 一样,您最终会备份 PostGIS 函数签名,因此转储必须针对相同的软件安装进行恢复,它不能用作升级过程的一部分。
38.3. 在线备份和恢复¶
在线备份和恢复允许管理员维护一套非常新的备份文件,而无需重复转储整个数据库。如果数据库经常进行插入和更新操作,那么在线备份可能比基本备份更好。
注意
了解在线备份的最佳方法是阅读 PostgreSQL 手册中有关连续存档和时间点恢复的相关章节。PostGIS 工作坊的这一部分将仅提供在线备份设置的简短快照。
38.3.1. 工作原理¶
PostgreSQL 不是持续写入主数据表,而是最初将更改存储在“预写日志” (WAL) 中。这些日志放在一起,完整记录了对数据库所做的所有更改。在线备份包括获取数据库主数据表的副本,然后获取之后生成的每个 WAL 的副本。
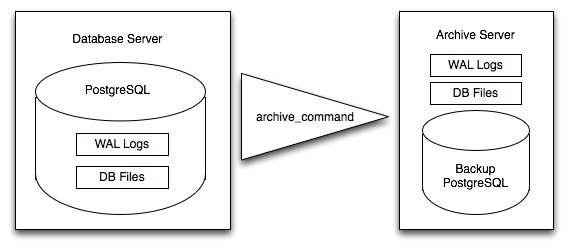
当需要恢复到新数据库时,系统从主数据副本开始,然后将所有 WAL 文件重放到数据库中。最终结果是恢复后的数据库与收到最后一个 WAL 时原始数据库的状态相同。
由于无论如何都会写入 WAL,并且将副本传输到存档服务器的计算成本很低,因此在线备份是一种有效的方法,可以保持系统非常新的备份,而无需进行密集的定期完整转储。
38.3.2. 存档 WAL 文件¶
设置在线备份要做的第一件事是创建存档方法。PostgreSQL 存档方法具有极致的灵活性:PostgreSQL 后端只是调用 archive_command 配置参数中指定的脚本。
这意味着存档可以像将文件复制到网络装载驱动器一样简单,也可以像加密并将文件通过电子邮件发送到远程存档一样复杂。您可以编写脚本的任何进程都可以用来存档文件。
要开启存档,我们将编辑 postgresql.conf,首先开启 WAL 存档
wal_level = archive
archive_mode = on
然后设置 archive_command 将我们的存档文件复制到安全的位置(根据需要更改目标路径)
# Unix
archive_command = 'test ! -f /archivedir/%f && cp %p /archivedir/%f'
# Windows
archive_command = 'copy "%p" "C:\\archivedir\\%f"'
重要的是,存档命令不要覆盖现有文件,因此 unix 命令包含初始测试,以确保文件不在那里。重要的是,如果复制过程失败,该命令返回非零状态。
更改完成后,您可以重新启动 PostgreSQL 以使其生效。
38.3.3. 创建基本备份¶
一旦到位了存档过程,就需要创建基本备份。
将数据库置于备份模式(这不会改变查询或数据更新的操作,它只是强制执行检查点并写入一个标签文件,指示何时创建备份)。
SELECT pg_start_backup('/archivedir/basebackup.tgz');
对于标签,使用备份文件的路径是一个好习惯,因为它有助于您跟踪备份的存储位置。
将数据库复制到存档位置
# Unix
tar cvfz /archivedir/basebackup.tgz ${PGDATA}
然后告诉数据库备份过程已完成。
SELECT pg_stop_backup();
当然,所有这些步骤都可以编写脚本用于常规的基础备份。
38.3.4. 从归档恢复¶
这些步骤取自 PostgreSQL 手册中关于连续归档和时间点恢复的内容。
如果服务器正在运行,请停止它。
如果您有足够的空间,请将整个集群数据目录和任何表空间复制到一个临时位置,以备日后使用。请注意,此预防措施将要求您的系统上有足够的可用空间来容纳现有数据库的两个副本。如果您没有足够的空间,您至少应该保存集群的 pg_xlog 子目录的内容,因为它可能包含在系统崩溃之前未归档的日志。
删除集群数据目录和您正在使用的任何表空间的根目录下的所有现有文件和子目录。
从文件系统备份中恢复数据库文件。确保以正确的属主(数据库系统用户,而不是 root!)和正确的权限恢复它们。如果您正在使用表空间,您应该验证 pg_tblspc/ 中的符号链接是否已正确恢复。
删除 pg_xlog/ 中存在的任何文件;这些文件来自文件系统备份,因此可能已过时而不是当前的。如果您根本没有归档 pg_xlog/,则使用正确的权限重新创建它,注意确保将其重新建立为符号链接(如果您之前是这样设置的)。
如果您在步骤 2 中保存了未归档的 WAL 段文件,请将它们复制到 pg_xlog/ 中。(最好是复制它们,而不是移动它们,这样如果出现问题并且您必须重新开始,您仍然拥有未修改的文件。)
在集群数据目录中创建一个恢复命令文件 recovery.conf(请参阅第 26 章)。您可能还想临时修改 pg_hba.conf,以防止普通用户连接,直到您确定恢复成功。
启动服务器。服务器将进入恢复模式并开始读取所需的已归档 WAL 文件。如果由于外部错误导致恢复终止,只需重新启动服务器,它将继续恢复。恢复过程完成后,服务器会将 recovery.conf 重命名为 recovery.done(以防止以后意外重新进入恢复模式),然后开始正常的数据库操作。
检查数据库的内容,以确保您已恢复到所需的状态。如果没有,请返回步骤 1。如果一切正常,请将 pg_hba.conf 恢复为正常状态,允许用户连接。
