27. 索引上的聚类¶
数据库检索信息的速度取决于它从磁盘读取数据的速度。小型数据库会完全进入 RAM 缓存,从而摆脱物理磁盘的限制,但对于大型数据库,访问物理磁盘将成为磁盘访问速度的限制因素。
数据是机会性地写入磁盘的,因此磁盘上存储数据的顺序与应用程序访问或组织数据的方式之间不一定存在任何关联。
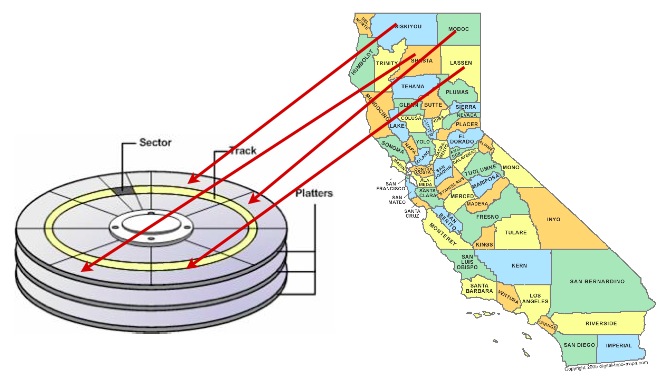
加速数据访问的一种方法是确保可能在同一结果集中一起检索的记录位于硬盘盘片上的相似物理位置。这称为“聚类”。
要使用的正确聚类方案可能很棘手,但有一个通用规则适用:索引为数据定义了一个自然的排序方案,该方案类似于检索数据时将使用的访问模式。
因此,在某些情况下,按照与索引相同的顺序对磁盘上的数据进行排序可以提供速度优势。
27.1. R 树上的聚类¶
空间数据往往在空间相关的窗口中被访问:想想 Web 或桌面应用程序中的地图窗口。窗口中的所有数据都具有相似的位置值(否则它就不会在窗口中!)
因此,基于空间索引的聚类对于将使用空间查询访问的空间数据是有意义的:相似的事物往往具有相似的位置。
让我们根据它们的空间索引对我们的 nyc_census_blocks 进行聚类
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
该命令按照空间索引 nyc_census_blocks_geom_gist 定义的顺序重写 nyc_census_blocks。你能感觉到速度上的差异吗?也许不能,因为原始数据可能已经具有一些预先存在的空间排序(这在 GIS 数据集中并不少见)。
27.2. 磁盘与内存/SSD¶
大多数现代数据库都使用 SSD 存储运行,其随机访问速度比旧的旋转磁介质快得多。此外,大多数现代数据库运行在足够小的数据之上,可以放入数据库服务器的 RAM 中,并最终作为操作系统“虚拟文件系统”缓存存储在那里。
聚类仍然有必要吗?
令人惊讶的是,是的。将空间中“彼此靠近”的记录在内存中“彼此靠近”会增加相关记录一起在服务器的“内存缓存层次结构”中向上移动的几率,从而加快内存访问速度。
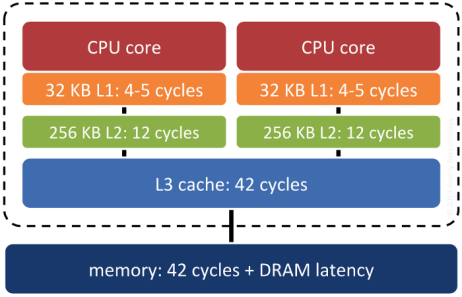
系统 RAM 不是现代计算机上最快的内存。在系统 RAM 和实际 CPU 之间有多个级别的缓存,并且底层操作系统和处理器将以块为单位在缓存层次结构中向上和向下移动数据。如果向上移动的块恰好包含系统接下来需要的数据…那将是一个巨大的胜利。将内存结构与空间结构相关联是增加这种胜利发生几率的一种方法。
27.3. 索引结构重要吗?¶
理论上,是的。实际上,并非如此。只要索引是数据“相当好”的空间分解,性能的主要决定因素将是实际表元组的顺序。
“无索引”和“索引”之间的差异通常是巨大的并且高度可测量的。“平庸索引”和“优秀索引”之间的差异通常需要非常仔细的测量才能辨别,并且可能对正在测试的工作负载非常敏感。
