30. 栅格¶
PostGIS 支持另一种称为栅格的空间数据类型。栅格数据与几何数据非常相似,都使用笛卡尔坐标和空间参考系统。但是,栅格数据不是矢量数据,而是表示为由像素和波段组成的 n 维矩阵。波段定义了您拥有的矩阵数量。每个像素存储一个值,该值对应于每个波段。因此,一个 3 波段栅格(例如 RGB 图像)对于每个像素将具有 3 个值,分别对应于红色、绿色和蓝色波段。
尽管您在电视屏幕上看到的漂亮图片是栅格,但栅格可能看起来并不那么令人兴奋。简而言之,栅格是一个固定在坐标系上的矩阵,其值可以表示您希望它们表示的任何内容。
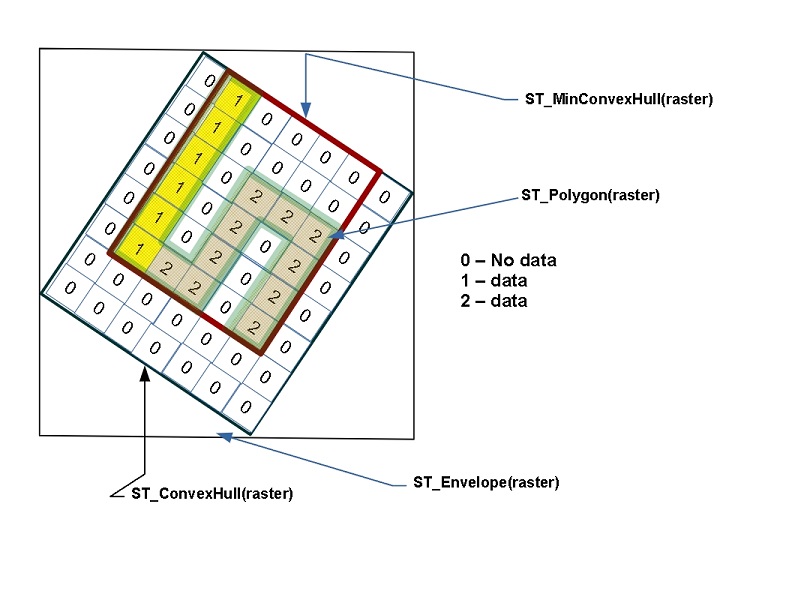
由于栅格存在于笛卡尔空间中,因此栅格可以与几何图形交互。PostGIS 提供了许多将栅格和几何图形都作为输入的函数。许多应用于栅格的操作将生成几何图形。常见的操作是 ST_Polygon、ST_Envelope、ST_ConvexHull 和 ST_MinConvexHull,如下所示。当您将栅格转换为几何图形时,输出的是栅格的 ST_ConvexHull。
栅格格式通常用于存储高程数据、温度数据、卫星数据以及表示诸如环境污染、人口密度和环境危害发生情况等主题数据。您可以使用栅格来存储任何具有有意义坐标位置的数字数据。唯一的限制是,对于特定波段中的所有数据,数字数据类型必须相同。
尽管可以在 PostGIS 中从头开始创建栅格数据,但更常见的方法是使用 PostGIS 打包的 raster2pgsql 命令行工具从各种格式加载栅格数据。在此之前,您必须通过运行以下命令在数据库中启用栅格支持:
CREATE EXTENSION postgis_raster;
30.1. 从几何图形创建栅格¶
我们将首先从矢量数据创建栅格数据,然后转向从栅格源加载数据的更激动人心的方法。您会发现栅格数据大量可用,并且通常可以从各种政府网站免费获得。
我们将从使用 ST_AsRaster 函数将一些几何图形转换为栅格开始,如下所示。
CREATE TABLE rasters (name varchar, rast raster);
INSERT INTO rasters(name, rast)
SELECT f.word, ST_AsRaster(geom, width=>150, height=>150)
FROM (VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_Letters(word) AS geom;
CREATE INDEX ix_rasters_rast
ON rasters USING gist(ST_ConvexHull(rast));
上面的示例使用 PostGIS 3.2+ ST_Letters 函数从字母形成的几何图形创建表 (rasters)。类似于几何图形,栅格可以利用空间索引。用于栅格的空间索引是一个功能索引,该索引对栅格的几何凸包进行索引。
您可以使用以下查询查看栅格的一些有用的元数据,该查询利用 postgis 栅格 ST_Count 函数来计算具有数据的像素数,并使用 ST_MetaData 函数来为我们的栅格提供各种有用的背景信息。
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
--------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
(2 rows)
注意
栅格函数有两个级别。有些函数(例如 ST_MetaData)在栅格级别工作,而有些函数(例如 ST_Count 函数和 ST_BandMetaData 函数)在波段级别工作。postgis 栅格中大多数在波段级别工作的函数一次只处理一个波段,并假定您想要的波段是 1。
如果您有一个多波段栅格,并且需要计算波段 1 以外的波段中没有无数据值的像素,则可以按以下方式显式指定波段号:ST_Count(rast,2)。
请注意,所有栅格的尺寸都是 150x150。这并不理想。这意味着,为了强制执行这一点,我们的栅格以各种方式被压缩。如果我们能看到眼前栅格的丑陋就好了。
30.2. 使用 raster2pgsql 加载栅格¶
raster2pgsql 是一个命令行工具,通常与 PostGIS 打包在一起。如果您使用的是 Windows 并且使用了应用程序堆栈构建器 PostGIS 捆绑包,您会在文件夹 C:\Program Files\PostgreSQL\15\bin 中找到 raster2pgsql.exe,其中 15 应替换为您正在运行的 PostgreSQL 版本。
如果您使用的是 Postgres.App,您会在其他 Postgres.app CLI 工具中找到 raster2pgsql。
在 Ubuntu 和 Debian 上,您需要
apt install postgis
安装 PostGIS 命令行工具。这可能会安装额外的 PostgreSQL 版本。您可以使用 pg_lsclusters 命令查看 Debian/Ubuntu 中的集群列表,并使用 pg_dropcluster 命令删除它们。
对于此练习和后续练习,我们将使用在文件 PG 栅格工作坊数据集 https://postgis.net.cn/stuff/workshop-data/postgis_raster_workshop.zip 中找到的 nyc_dem.tif。对于一些几何/栅格示例,我们还将使用从先前章节加载的 NYC 数据。为了避免加载 tif,您可以使用 pg_restore 命令行工具或 pgAdmin 恢复菜单,在数据库中还原 zip 文件中包含的 nyc_dem.backup。
注意
此栅格数据来源于 NYC DEM 1 英尺整数,这是一个 3GB DEM tif 文件,表示相对于海平面的高程,移除了建筑物和水上部分。然后,我们创建了其分辨率较低的版本。
raster2pgsql 工具类似于 shp2gpsql,不同之处在于,它不是将 ESRI shapefile 加载到 PostGIS 几何/地理表中,而是将任何 GDAL 支持的栅格格式加载到栅格表中。就像 shp2pgsql 一样,您可以向其传递源的空间参考 ID (SRID)。与 shp2pgsql 不同,如果您的源数据具有合适的元数据,它可以推断源数据的空间参考系统。
有关所有可能的开关的完整说明,请参阅 raster2pgsql 选项。
raster2pgsql 提供的其他一些值得注意的选项(我们不会介绍)是:
能够表示源的 SRID。相反,我们将依赖 raster2pgsql 的猜测技巧。
能够设置 nodata 值,如果未指定,raster2pgsql 会尝试从文件中推断。
能够加载数据库外栅格。
要加载我们文件夹中的所有 tif 文件并创建概览,我们将运行以下命令。
raster2pgsql -d -e -l 2,3 -I -C -M -F -Y -t 256x256 *.tif nyc_dem | psql -d nyc
-d:如果表已存在,则删除表
上面的命令使用 -e 来立即加载,而不是在事务中提交
-C:设置栅格约束,这对于 raster_columns 显示信息很有用。您可能需要与 -x 结合使用,以排除范围约束,这是一个检查速度较慢的约束,也会妨碍将来在表中加载数据。
-M:在加载后进行 vacuum 和 analyze,以改进查询计划器统计信息
-Y:以 50 个为一批使用复制。如果您运行的是 PostGIS 3.3 或更高版本,可以使用 -Y 1000 使复制以 1000 个为一批,甚至更高。这将运行得更快,但会使用更多内存。
-l 2,3:创建概览表:o_2_ncy_dem 和 o_3_nyc_dem。这对于查看数据很有用。
-I:创建空间索引
-F:添加文件名,如果您只有一个 tif 文件,这有点毫无意义。如果您有多个文件,这将有助于告诉您每个行来自哪个文件。
-t:设置块大小。请注意,如果您不确定最佳大小,请改用 -t auto,raster2pgql 将使用与 tif 中相同的平铺。输出将告诉您它选择的块大小。如果看起来很大或很奇怪,请取消。原始文件的大小为 300x7,这并不理想。
使用 psql 针对数据库运行生成的 sql。如果您想转储到文件,请使用 > nyc_dem.sql
在此示例中,我们只有一个 tif 文件,因此我们可以指定完整文件名,而不是 *.tif。如果文件不在当前目录中,您还可以使用 *.tif 指定文件夹路径。
注意
如果您使用的是 Windows 并且需要引用文件夹,请确保包含盘符,例如 C:/workshop/*.tif
您经常会在 PostGIS 术语中听到 栅格切片 和 栅格 这两个词交替使用。栅格切片实际上对应于栅格列中的特定栅格,它是较大栅格的子集,例如我们刚刚加载的这个 NYC dem 数据。这是因为当栅格从大型栅格文件加载到 PostGIS 中时,它们会被切分成多行以使其易于管理。然后,每行中的每个栅格都是较大栅格的一部分。每个切片覆盖由您指定的块大小表示的相同大小区域。遗憾的是,栅格受到 1GB PostgreSQL TOAST 限制以及缓慢的解冻过程的限制,因此我们需要进行分割才能获得不错的性能,甚至才能存储它们。
30.3. 在浏览器中查看栅格¶
虽然 pgAdmin 和 psql 目前还没有查看 PostGIS 栅格的功能,但我们有几种选择。对于较小的栅格,最简单的方法是使用 PostGIS 内置的栅格函数(例如 ST_AsPNG 或 ST_AsGDALRaster)输出为 Web 友好的栅格格式(如 PNG),这些函数在PostGIS 栅格输出函数中列出。随着栅格变大,您需要升级到 QGIS 等工具来查看它们的全部效果,或者使用 GDAL 系列命令行工具(如 gdal_translate)将它们导出为其他栅格格式。但请记住,PostGIS 栅格是为分析而构建的,而不是为了生成漂亮的图片供您查看。
需要注意的是,默认情况下,所有不同的栅格类型输出都是禁用的。要使用这些输出,您需要启用驱动程序,全部或部分启用,详见启用 GDAL 栅格驱动程序。
SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
如果您不想为每个连接都执行此操作,可以使用以下方法在数据库级别进行设置:
ALTER DATABASE nyc SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
每个新的数据库连接都将使用该设置。
运行以下查询,并将输出复制并粘贴到 Web 浏览器的地址栏中。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello';

对于目前创建的栅格,我们没有指定波段的数量,也没有定义它们与地球的关系。因此,我们的栅格具有未知的空间参考系统 (0)。
您可以将栅格的外骨骼视为几何图形。一个包裹在几何外壳中的矩阵。为了进行有用的分析,我们需要对栅格进行地理配准,这意味着我们希望每个像素(矩形)代表空间的一些有意义的区域。
ST_AsRaster 有许多重载表示形式。之前的示例使用了最简单的实现,并接受了默认参数,即 8BUI 和 1 个波段,无数据值为 0。如果需要使用其他变体,应使用命名参数调用语法,以免意外地陷入错误的函数变体或出现 **function is not unique** 错误。
如果从具有空间参考系统的几何图形开始,最终将得到具有相同空间参考系统的栅格。在接下来的示例中,我们将在纽约以明亮的欢快色彩绘制文字。我们还将使用像素比例而不是宽度和高度,以便我们的栅格像素大小代表 1 米 x 1 米的空间。
INSERT INTO rasters(name, rast)
SELECT f.word || ' in New York' ,
ST_AsRaster(geom,
scalex => 1.0, scaley => -1.0,
pixeltype => ARRAY['8BUI', '8BUI', '8BUI'],
value => CASE WHEN word = 'Hello' THEN
ARRAY[10,10,100] ELSE ARRAY[10,100,10] END,
nodataval => ARRAY[0,0,0], gridx => NULL, gridy => NULL
) AS rast
FROM (
VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_SetSRID(
ST_Translate(ST_Letters(word),586467,4504725), 26918
) AS geom;
如果我们查看这个,会看到一个未被压缩的彩色几何图形。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello in New York';

对栅格重复此操作
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Raster in New York';

更重要的是,如果我们重新运行
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
观察纽约条目的元数据。它们具有纽约州平面米空间参考系统。它们也具有相同的比例。由于每个单位是 1x1 米,因此单词 **Raster** 的宽度现在比 **Hello** 更宽。
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
-------------------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+-------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
Hello in New York | 8786 | 586467 | 4504802.1 | 184 | 78 | 1 | -1 | 0 | 0 | 26918 | 3
Raster in New York | 10544 | 586467 | 4504800.4 | 258 | 76 | 1 | -1 | 0 | 0 | 26918 | 3
(4 rows)
30.4. 栅格空间目录表¶
与几何和地理类型类似,栅格也有一组目录,用于显示数据库中的所有栅格列。这些是 raster_columns 和 raster_overviews。
30.4.1. raster_columns¶
raster_columns 视图是 geometry_columns 和 geography_columns 的同级视图,为栅格列提供大致相同的数据以及更多数据。
SELECT *
FROM raster_columns;
浏览表格,您会发现以下内容:
r_table_catalog | r_table_schema | r_table_name | r_raster_column | srid | scale_x | scale_y | blocksize_x | blocksize_y | same_alignment | regular_blocking | num_bands | pixel_types | nodata_values | out_db | extent | spatial_index
----------------+----------------+--------------+-----------------+------+---------+---------+-------------+-------------+----------------+------------------+-----------+-------------+---------------+--------+--------+---------------
nyc | public | rasters | rast | 0 | | | | | f | f | | | | | | t
nyc | public | nyc_dem | rast | 2263 | 10 | -10 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_2_nyc_dem | rast | 2263 | 20 | -20 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_3_nyc_dem | rast | 2263 | 30 | -30 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
(4 rows)
对于 rasters 表,令人失望的一行,大部分信息未填写。
与几何和地理不同,栅格不支持类型修饰符,因为类型修饰符空间太有限,并且有比类型修饰符能容纳的更重要的属性。
栅格改为依赖约束,并将这些约束作为视图的一部分读取。
查看我们使用 raster2pgsql 加载的表格中的其他行。因为我们使用了 -C 开关,raster2pgsql 为 srid 和它可以从 tif 读取或我们传入的其他信息添加了约束。使用 -l 开关生成的概览表 o_2_nyc_dem 和 o_3_nyc_dem 也将显示出来。
让我们尝试向我们的表中添加一些约束。
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
您会收到一大堆关于您的栅格数据混乱且无法约束的通知。如果再次查看 raster_columns,仍然是关于 rasters 的许多空白行的令人失望的故事。
为了应用约束,表格中的所有栅格必须至少可以通过一条规则进行约束。
也许我们可以这样做,让我们假装所有数据都在纽约州平面中。
UPDATE rasters SET rast = ST_SetSRID(rast,26918)
WHERE ST_SRID(rast) <> 26918;
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
SELECT r_table_name AS t, r_raster_column AS c, srid,
blocksize_x AS bx, blocksize_y AS by, scale_x AS sx, scale_y AS sy,
ST_AsText(extent) AS e
FROM raster_columns
WHERE r_table_name = 'rasters';
啊,取得进展了
t | c | srid | bx | by | sx | sy | e
----------+------+-------+-----+-----+----+----+------------------------------------------
rasters | rast | 26918 | 150 | 150 | | | POLYGON((0 -0.90000000000..
(1 row)
您可以约束的栅格越多,您将看到填充的列越多,并且您将能够在栅格中的所有图块上执行更多操作。请记住,在某些情况下,您可能不想应用所有约束。
例如,如果您计划将更多数据加载到栅格表中,则需要跳过范围约束,因为这要求所有栅格都在范围约束的范围内。
30.4.2. raster_overviews¶
栅格概览列同时出现在 raster_columns 元目录和另一个名为 raster_overviews 的元目录中。概览主要用于加快在高缩放级别下的查看速度。它们还可以用于快速的粗略分析,提供不太准确的统计信息,但速度比应用于原始栅格表快得多。
要检查概览,请运行
SELECT *
FROM raster_overviews;
您将看到输出:
o_table_catalog | o_table_schema | o_table_name | o_raster_column | r_table_catalog | r_table_schema | r_table_name | r_raster_column | overview_factor
----------------+----------------+--------------+-----------------+-----------------+----------------+--------------+-----------------+-----------------
nyc | public | o_2_nyc_dem | rast | nyc | public | nyc_dem | rast | 2
nyc | public | o_3_nyc_dem | rast | nyc | public | nyc_dem | rast | 3
(2 rows)
raster_overviews 表仅提供 overview_factor 和父表的名称。所有这些信息都可以通过 raster2pgsql 的概览命名约定自己推断出来。
overview_factor 告诉您该行相对于其父项的分辨率。overview_factor 为 2 表示 2x2 = 4 个图块可以放入一个 overview_2 图块中。类似地,overview_factor 为 3 表示可以将原始的 2x2x2 = 8 个图块塞入 overview_3 图块中。
30.5. 常用栅格函数¶
postgis_raster 扩展有 100 多个函数可供选择。PostGIS 栅格功能是仿照 PostGIS 几何支持设计的。您会发现栅格和几何之间在有意义的地方存在函数重叠。您将使用的常用函数(在几何世界中具有等效函数)有 ST_Intersects、ST_SetSRID、ST_SRID、ST_Union、ST_Intersection 和 ST_Transform。
除了这些重叠的函数外,它还支持栅格之间以及栅格和几何之间的 && 重叠运算符。它还提供了许多与几何结合使用或特定于栅格的函数。
您需要像 ST_Union 这样的函数来重建区域。由于分析的像素越多,性能就越慢,因此您需要一个快速的函数 ST_Clip 来将栅格裁剪到您分析感兴趣的部分。
最后,您需要 ST_Intersects 或 && 来放大包含您感兴趣区域的栅格图块。&& 运算符比 ST_Intersects 速度更快。两者都可以利用栅格空间索引。我们将在介绍其他部分之前先介绍这些基本函数,我们将在其他部分将它们与其他栅格和几何函数一起使用。
30.5.1. 使用 ST_Union 合并栅格¶
栅格的 ST_Union 函数,就像几何等效函数 ST_Union 一样,将一组栅格聚合到一个栅格中。但是,就像几何一样,并非所有栅格都可以组合在一起,但是栅格联合的规则比几何规则更复杂。对于几何图形,您只需要具有相同的空间参考系统,但是对于栅格,这还不够。
如果您尝试以下操作:
SELECT ST_Union(rast)
FROM rasters;
您将立即受到错误的惩罚:
ERROR: rt_raster_from_two_rasters: 提供的两个栅格不具有相同的对齐方式 SQL state: XX000
什么是相同的对齐方式,它阻止您合并宝贵的栅格?
为了合并栅格,它们需要位于同一个网格上。这意味着它们必须具有相同的像素大小、相同的方向(倾斜)、相同的空间参考系统,并且它们的像素不能相互切割,这意味着它们共享相同的世界像素网格。
如果您尝试相同的查询,只是使用我们精心放置在纽约的文字:
同样,出现相同的错误。这些是相同的空间参考系统,相同的像素大小,但是仍然不够好。因为它们的网格是错位的。
我们可以通过稍微移动左上角的 y 坐标来解决此问题,然后再试一次。如果我们的像素大小是整数,并且网格从整数级别开始,那么像素就不会相互切割。
UPDATE rasters SET rast = ST_SetUpperLeft(rast,
ST_UpperLeftX(rast)::integer,
ST_UpperLeftY(rast)::integer)
WHERE name LIKE '%New York';
SELECT ST_Union(rast ORDER BY name)
FROM rasters
WHERE name LIKE '%New York%';
瞧,它成功了,如果我们查看,我们会看到这样的内容:

注意
如果您不清楚为什么栅格不具有相同的对齐方式,可以使用函数 ST_SameAlignment,它将比较 2 个栅格或一组栅格,并告诉您它们是否具有相同的对齐方式。如果启用了通知,则 NOTICE 将告诉您所讨论栅格的哪些方面不一致。ST_NotSameAlignmentReason 不仅会输出通知,还会输出原因。但是,它一次只能处理两个栅格。
ST_Union(raster) 栅格函数与 ST_Union(geometry) 几何函数的主要区别在于,它允许一个名为 *uniontype* 的参数。如果您未指定此参数,则默认情况下此参数设置为 LAST,这意味着在栅格像素值重叠的情况下,采用 **LAST** 栅格像素值。一般来说,在波段中标记为无数据的像素会被忽略。
就像 PostgreSQL 中的大多数聚合一样,您可以将 ORDER BY 子句作为函数调用的一部分,如前面的示例所示。指定顺序可以控制哪个栅格优先。因此,在前面的示例中,*Raster* 优先于 *Hello*,因为 *Raster* 在字母表中排在最后。
请注意,如果您切换顺序
SELECT ST_Union(rast ORDER BY name DESC)
FROM rasters
WHERE name LIKE '%New York%';

那么Hello会覆盖Raster,因为 Hello 现在是最后叠加的。
FIRST 并集类型与 LAST 相反。
但有时,LAST 可能不是正确的操作。假设我们的栅格代表来自两个不同设备的两个不同的观测数据集。这些设备测量的是同一事物,并且我们不确定当它们交叉时哪个是正确的,因此我们希望取结果的平均值。我们会这样做
SELECT ST_Union(rast, 'MEAN')
FROM rasters
WHERE name LIKE '%New York%';
瞧,它成功了,如果我们查看,我们会看到这样的内容:

因此,我们不是覆盖,而是将两种力量混合在一起。在 MEAN 并集类型的情况下,指定顺序没有意义,因为结果将是重叠像素值的平均值。
请注意,对于几何图形,由于几何图形是矢量,因此除了存在与否之外没有其他值,因此当两个矢量相交时,如何组合两个矢量实际上没有任何歧义。
我们忽略的栅格 ST_Union 的另一个功能是,您应该返回所有波段还是仅返回某些波段。当您不指定要并集的波段时, ST_Union 将组合相同波段的数字,并使用 LAST 并集策略。如果您有多个波段,这可能不是您想要的操作。也许您只想并集第二个波段。在这种情况下,是绿色波段,并且您想要像素值的计数。
SELECT ST_BandPixelType(ST_Union(rast, 2, 'COUNT'))
FROM rasters
WHERE name LIKE '%New York%';
st_bandpixeltype
------------------
32BUI
(1 row)
请注意,对于 COUNT 并集类型,它计算填充的像素数量并返回该值,结果始终是 32BUI ,类似于在 sql 中执行 COUNT 时,结果始终是 bigint,以适应大的计数。
在其他情况下,波段像素类型不会更改,并且设置为最大值,如果数值超出类型的边界,则会四舍五入。为什么会有人想计算在某个位置相交的像素?假设您的每个栅格代表警察中队和该区域的逮捕事件。每个值可能代表不同的逮捕原因。您正在统计每个区域的逮捕次数,因此您只关心逮捕的计数。
或者,也许您想处理所有波段,但您想要不同的策略。
SELECT ST_Union(rast, ARRAY[(1, 'MAX'),
(2, 'MEAN'),
(3, 'RANGE')]::unionarg[])
FROM rasters
WHERE name LIKE '%New York%';
使用 ST_Union 函数的 unionarg[] 变体,您还可以混排波段的顺序。
30.5.2. 使用 ST_Intersects 裁剪栅格¶
ST_Clip 函数是 PostGIS 栅格中最广泛使用的函数之一。主要原因是您需要检查或执行操作的像素越多,处理速度就越慢。 ST_Clip 将您的栅格裁剪到您感兴趣的区域,因此您可以将您的操作隔离到该区域。
此函数也很特别,因为它利用了几何图形的力量来帮助栅格分析。为了减少像素的数量,ST_Union 必须处理,每个栅格首先被裁剪到我们感兴趣的区域。
SELECT ST_Union( ST_Clip(r.rast, g.geom) )
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
此示例展示了多个函数协同工作。所使用的 ST_Intersects 函数是与 postgis_raster 一起打包的函数,可以相交 2 个栅格或一个栅格和一个几何图形。类似于几何图形 ST_Intersects , 栅格 ST_Intersects 可以利用栅格或几何图形表上的空间索引。
注意
默认情况下,ST_Clip 将排除像素质心与几何图形不相交的像素。对于大像素来说,这可能很烦人,您可能更愿意在像素的任何部分接触到几何图形时将其包含在内。PostGIS 3.5 中引入了 touched 参数。将您的 ST_Clip(r.rast, g.geom) 替换为 ST_Clip(r.rast, g.geom, touched => true) ,并且任何以任何方式与您的几何图形相交的像素都将被包括在内。
30.6. 将栅格转换为几何图形¶
栅格可以很容易地变形为几何图形。
30.6.1. 使用 ST_Polygon 的栅格多边形¶
让我们从之前的示例开始,但是使用 ST_Polygon 函数将其转换为多边形。
SELECT ST_Polygon(ST_Union( ST_Clip(r.rast, g.geom) ))
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
如果您单击 pgAdmin 中的几何图形查看器,您可以毫无任何技巧地看到它的全部荣耀。
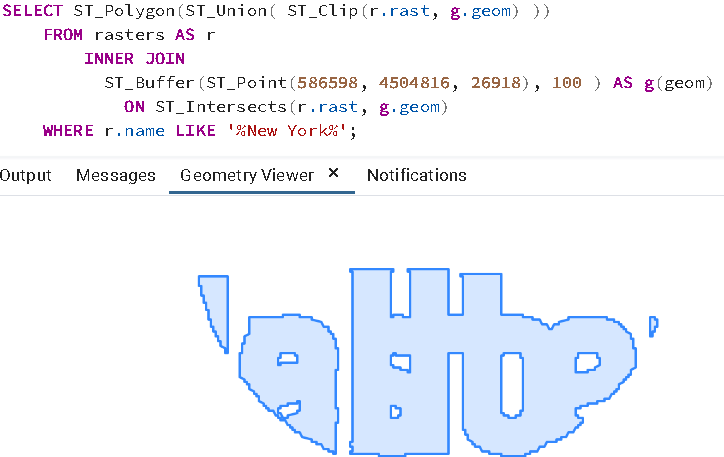
ST_Polygon 考虑特定波段中具有值(不是无数据)的所有像素,并将其转换为几何图形。像栅格中的许多其他函数一样,ST_Polygon 只考虑 1 个波段。如果未指定波段,它将只考虑第一个波段。
30.6.2. 使用 ST_PixelAsPolygons 的栅格像素矩形¶
另一个常用的函数是 ST_PixelAsPolygons 函数。您应该很少在没有先裁剪的情况下对大型栅格使用 ST_PixelAsPolygons ,因为您将最终得到数百万行,每行对应一个像素。
ST_PixelAsPolygons 返回一个包含 geom、val、x 和 y 的表。其中 x 是列号,y 是栅格中的行号。
与其他栅格函数类似,ST_PixelAsPolygons 一次处理一个波段,如果未指定波段,则处理波段 1。默认情况下,它也只返回具有值的像素。
SELECT gv.*
FROM rasters AS r
CROSS JOIN LATERAL ST_PixelAsPolygons(rast) AS gv
WHERE r.name LIKE '%New York%'
LIMIT 10;
它输出
如果我们使用几何图形查看器进行检查,我们会看到
如果我们想要所有波段的所有像素,我们需要执行如下操作。请注意此示例与之前的示例的不同之处。
1. 设置 exclude_nodata_value 以确保返回所有像素,以便我们的调用集返回相同数量的行。函数输出的行将自然地按相同顺序排列。
2. 使用 PostgreSQL ROWS FROM 构造函数,并将函数输出中的每一组列都使用名称进行别名。例如,波段 1 的列(geom、val、x、y)被重命名为 g1、v1、x1、x2
SELECT pp.g1, pp.v1, pp.v2, pp.v3
FROM rasters AS r
CROSS JOIN LATERAL
ROWS FROM (
ST_PixelAsPolygons(rast, 1, exclude_nodata_value => false ),
ST_PixelAsPolygons(rast, 2, exclude_nodata_value => false),
ST_PixelAsPolygons(rast, 3, exclude_nodata_value => false )
) AS pp(g1, v1, x1, y1,
g2, v2, x2, y2,
g3, v3, x3, y3 )
WHERE r.name LIKE '%New York%'
AND ( pp.v1 = 0 OR pp.v2 > 0 OR pp.v3 > 0) ;
注意
我们在这些示例中使用了 CROSS JOIN LATERAL,因为我们想明确我们在做什么。由于这些都是返回集合的函数,您可以将 CROSS JOIN LATERAL 替换为 , 作为简写形式。我们将在下一组示例中使用 ,
30.6.3. 使用 ST_DumpAsPolygons 转储多边形¶
栅格还引入了一种称为 geomval 的附加复合类型。将 geomval 视为几何图形和栅格的后代。它包含几何图形,并且它包含像素值。
您会发现多个返回 geomval 的栅格函数。
常用的输出 geomval 的函数是 ST_DumpAsPolygons,它返回一组具有相同值的连续像素作为多边形。同样,默认情况下,它只会检查波段 1,并且除非您覆盖,否则会排除无数据值。此示例仅从波段 2 中选择多边形。您还可以将过滤器应用于这些值。对于大多数用例,ST_DumpAsPolygons 比 ST_PixelAsPolygons 更好的选择,因为它将返回少得多的行。
这将输出 6 行,并返回与“Raster”中的字母对应的多边形。
SELECT gv.geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
AND gv.val = 100;
请注意,它不返回单个几何图形,因为它会找到形成多边形的具有相同值的连续像素集。即使所有这些值都相同,它们也不是连续的。

生成更复杂几何图形的常见方法是按值分组并进行并集。
SELECT ST_Union(gv.geom) AS geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
GROUP BY gv.val;
这将为您返回 2 行,分别对应于单词“Raster”和“Hello”。
30.7. 统计信息¶
要了解栅格,最重要的是它们是用于以数组形式存储数据的统计工具,您可能会碰巧能够在屏幕上使它们看起来很漂亮。
您可以在 栅格波段统计中找到这些统计函数的菜单。
30.7.1. ST_SummaryStatsAgg 和 ST_SummaryStats¶
如果想要一组栅格的所有统计信息,请使用函数 ST_SummaryStatsAgg。
此查询大约需要 10 秒钟,并为您提供整个表的摘要
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem;
输出
count | sum | mean | stddev | min | max
-----------+------------+------------------+------------------+-----+-----
246794100 | 4555256024 | 18.4577184948911 | 39.4416860598687 | 0 | 411
(1 row)
这告诉我们有很多像素,并且我们的最大海拔高度为 411 英尺。
如果您已构建概览,并且只需要对最小值、最大值和平均值的粗略估计,请使用您的一个概览。下一个查询返回的最小值、最大值和平均值与之前的查询大致相同,但大约需要 1 秒而不是 10 秒。
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem ;
现在有了这些信息,我们可以提出更多问题。
30.7.2. ST_Histogram¶
通常,您不会想要整个表的统计信息,而是只想要特定区域的统计信息,在这种情况下,您还需要使用我们的老朋友 ST_Intersects 和 ST_Clip 。如果您还需要一个没有聚合版本的栅格统计函数,您还需要携带 ST_Union 。
对于下一个示例,我们将使用另一个没有聚合等效项的统计函数 ST_Histogram,并且对于此特定变体,它是一个返回集合的函数。我们使用与之前一些示例相同的感兴趣区域,但是我们还需要使用几何图形 ST_Transform 将我们的纽约州平面米几何图形转换为我们的纽约市州平面英尺栅格。转换几何图形几乎总是比转换栅格的性能更高,而且如果您的几何图形只是单个图形,则更是如此。
SELECT (ST_Quantile( ST_Union( ST_Clip(r.rast, g.geom) ), ARRAY[0.25,0.50,0.75, 1.0] )).*
FROM nyc_dem AS r
INNER JOIN
ST_Transform(
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ),
2263) AS g(geom)
ON ST_Intersects(r.rast, g.geom);
上面的查询在 60 毫秒内完成并输出
quantile | value
----------+-------
0.25 | 52
0.5 | 57
0.75 | 68
1 | 78
(4 rows)
30.8. 创建派生栅格¶
PostGIS 栅格附带了许多用于编辑栅格的函数。这些函数既用于编辑,也用于创建派生栅格数据集。您可以在 栅格编辑器和栅格管理中找到这些列表。
30.8.1. 使用 ST_Transform 转换栅格¶
我们的大部分数据都采用纽约州平面米(SRID:26918),但是我们的 DEM 栅格数据集采用纽约州平面英尺(SRID:2263)。为了获得最不麻烦的工作流程,我们需要我们的核心数据集采用相同的空间参考系统。
栅格 ST_Transform 是最适合此项工作的函数。
为了在纽约州平面米制坐标系中创建一个新的纽约市 DEM 数据集,我们将执行以下操作:
CREATE TABLE nyc_dem_26918 AS
WITH ref AS (SELECT ST_Transform(rast,26918) AS rast
FROM nyc_dem LIMIT 1)
SELECT r.rid, ST_Transform(r.rast, ref.rast) AS rast, r.filename
FROM nyc_dem AS r, ref;
上述操作在我的系统上花费了大约 1.5 分钟。对于更大的数据集,则需要更长的时间。
前面提到的示例使用了 ST_Transform 栅格函数的两个变体。第一个变体用于获取参考栅格,该参考栅格将用于转换其他栅格图块,以确保所有图块具有相同的对齐方式。请注意,使用的 ST_Transform 的第二个变体甚至不需要输入 SRID。这是因为 SRID 以及所有像素比例和块大小都是从参考栅格中读取的。如果您使用 ST_Transform(rast, srid) 形式,则所有栅格的对齐方式可能会不同,从而无法对其应用 ST_Union 等操作。
前面提到的 ST_Transform 方法的唯一问题是,在进行转换时,转换后的数据通常会存在于其他图块中。如果您仔细观察上述输出,通过输出栅格的凸包,在下一个示例中,您会看到边界周围恼人的重叠。
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
在 pgAdmin 中查看会类似于:

30.8.2. 使用 ST_MakeEmptyCoverage 创建均匀平铺的栅格¶
一个更好的方法(尽管速度稍慢)是使用 ST_MakeEmptyCoverage 从头开始定义您自己的覆盖范围图块结构,然后为每个新图块查找相交的图块,并使用 ST_Union 将它们合并,然后使用 ST_Transform(ref, ST_Union…) 来创建每个图块。
为此,我们将使用之前学习的一些函数。
DROP TABLE IF EXISTS nyc_dem_26918;
CREATE TABLE nyc_dem_26918 AS
SELECT ROW_NUMBER() OVER(ORDER BY t.rast::geometry) AS rid,
ST_Union(ST_Clip( ST_Transform( r.rast, t.rast, 'Bilinear' ), t.rast::geometry ), 'MAX') AS rast
FROM (SELECT ST_Transform(
ST_SetSRID(ST_Extent(rast::geometry),2263)
, 26918) AS geom
FROM nyc_dem
) AS g, ST_MakeEmptyCoverage(tilewidth => 256, tileheight => 256,
width => (ST_XMax(g.geom) - ST_XMin(g.geom))::integer,
height => (ST_YMax(g.geom) - ST_YMin(g.geom))::integer,
upperleftx => ST_XMin(g.geom),
upperlefty => ST_YMax(g.geom),
scalex => 3.048,
scaley => -3.048,
skewx => 0., skewy => 0., srid => 26918) AS t(rast)
INNER JOIN nyc_dem AS r
ON ST_Transform(t.rast::geometry, 2263) && r.rast
GROUP BY t.rast;
重复与前面相同的练习:
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
在 pgAdmin 中查看,我们不再有重叠。

在我的系统上,这花费了大约 10 分钟,并返回了 3879 行。创建表后,我们将要像往常一样添加空间索引、主键和约束,如下所示:
ALTER TABLE nyc_dem_26918
ADD CONSTRAINT pk_nyc_dem_26918 PRIMARY KEY(rid);
CREATE INDEX ix_nyc_dem_26918_st_convexhull_gist
ON nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
SELECT AddRasterConstraints('nyc_dem_26918'::name, 'rast'::name);
ANALYZE nyc_dem_26918;
对于此数据集,这应该在 2 分钟内完成。
30.8.3. 使用 ST_CreateOverview 创建概览表¶
与原始数据集一样,拥有概览表对于加速某些操作的性能将非常有用。ST_CreateOverview 是适用于此目的的函数。您也可以使用 ST_CreateOverview 来创建概览,如果在 raster2pgsql 加载期间您忽略了创建概览,或者您决定需要更多的概览。
我们将像对原始数据集一样,使用此代码创建级别 2 和 3 的概览。
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 2);
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 3);
遗憾的是,此过程需要一段时间,并且行数越多,花费的时间就越长,因此请耐心等待。对于此数据集,概览因子 2 花费了大约 3-5 分钟,概览因子 3 花费了 1 分钟。
ST_CreateOverView 函数还会添加所需的约束,因此列会以完整详细信息显示在 raster_columns 和 raster_overviews 目录中。但是,它不会向它们添加索引,也不会添加 rid 列。除非您需要使用主键进行编辑,否则 rid 列可能不是必需的。您可能需要一个索引,可以使用以下方法创建:
CREATE INDEX ix_o_2_nyc_dem_26918_st_convexhull_gist
ON o_2_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
CREATE INDEX ix_o_3_nyc_dem_26918_st_convexhull_gist
ON o_3_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
注意
ST_CreateOverview 有一个可选参数,用于表示采样方法。如果未指定,则使用默认的 NearestNeighbor,它通常计算速度最快,但可能不是最理想的。重采样方法超出了本研讨会的范围。
30.9. 栅格和几何图形的交集¶
有几个常用函数用于计算栅格和几何图形的交集。我们已经看到了 ST_Clip 的作用,它返回栅格和几何图形的交集作为栅格,但还有其他函数。对于点数据,最常用的是 ST_Value,然后是 ST_Intersection,它有几个重载,有些返回栅格,有些返回一组 geomval。
30.9.1. 几何点处的像素值¶
如果您需要根据多个临时几何点的交集从栅格返回值,您将使用 ST_Value 或其最近的相对函数 ST_NearestValue。
SELECT g.geom, ST_Value(r.rast, g.geom) AS elev
FROM nyc_dem_26918 AS r
INNER JOIN
(SELECT id, geom
FROM nyc_homicides
WHERE weapon = 'gun') AS g
ON r.rast && g.geom;
此示例大约需要 1 秒来返回 2444 行。如果您使用 ST_Intersects 而不是 &&,则该过程将花费大约 3 秒。ST_Intersects 速度较慢的原因是,它在某些情况下会执行额外的逐像素检查。如果您希望所有点都用栅格集中的数据表示,并且您的栅格表示覆盖范围(一组连续的非重叠栅格图块),则 && 通常是速度更快的选项。
如果您的栅格数据不是密集填充的,或者您有重叠的栅格(例如,它们表示时间上的不同观测),或者它们是倾斜的(未与轴对齐),那么使用 ST_Intersects 排除假阳性具有优势。
30.9.2. ST_Intersection 栅格样式¶
就像您可以使用 ST_Intersection 计算两个几何图形的交集一样,您可以使用 栅格 ST_Intersection 计算两个栅格或一个栅格和一个几何图形的交集。
您从此得到的结果有两种不同的类型:
将几何图形与栅格相交,您将获得一组 geomval 后代。可能只有一个,但大多数情况下有很多。
将 2 个栅格相交,您将获得单个 raster 返回。
栅格交集和几何交集的黄金法则是,双方都必须具有相同的空间参考系统。对于栅格/栅格,它们还必须具有相同的对齐方式。
这是一个示例,回答了您可能一直很好奇的问题。如果我们根据高程值将我们的高程划分为 5 个桶,哪个高程范围导致了最多的枪支死亡事件?根据我们之前的汇总统计数据,我们知道在我们的纽约市 DEM 数据集中,0 是最低值,411 是最高值,因此我们将其用作 width_bucket 调用的最小值和最大值。
SELECT ST_Transform(ST_Union(gv.geom),4326) AS geom ,
MIN(gv.val) AS min_elev, MAX(gv.val) AS max_elev,
count(g.id) AS count_guns
FROM nyc_dem_26918 AS r
INNER JOIN nyc_homicides AS g
ON ST_Intersects(r.rast, g.geom)
CROSS JOIN
ST_Intersection( g.geom,
ST_Clip(r.rast,ST_Expand(g.geom, 4) )
) AS gv
WHERE g.weapon = 'gun'
GROUP BY width_bucket(gv.val, 0, 411, 5)
ORDER BY width_bucket(gv.val, 0, 411, 5);
枪支杀人事件和高程之间是否存在重要的关联?可能没有。
让我们看一下栅格/栅格交集:
SELECT ST_Intersection(r1.rast, 1, r2.rast, 1, 'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
我们得到的是两行 NULL 值,如果您的 PostgreSQL 设置为显示通知,您将看到:
通知:提供的两个栅格没有相同的对齐方式。返回 NULL
为了解决这个问题,我们可以使用 ST_Resample 将一个栅格与另一个栅格对齐。
SELECT ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1,
'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
让我们也将其汇总为单个统计记录:
SELECT (
ST_SummaryStatsAgg(
ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1, 'BAND1'),
1, true)
).*
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
输出:
count | sum | mean | stddev | min | max
-------+-------+-----------------+------------------+-----+-----
2075 | 99536 | 47.969156626506 | 9.57974836865737 | 33 | 62
(1 row)
30.10. 地图代数函数¶
地图代数的概念是您可以对像素值进行数学运算。前面介绍的 ST_Union 和 ST_Intersection 函数是地图代数的一种特殊的快速情况。然后是 ST_MapAlgebra 系列函数,这些函数允许您定义自己的复杂数学运算,但代价是性能下降。
人们习惯于直接使用 ST_MapAlgebra,可能是因为这个名字听起来很酷很复杂。谁不想告诉他们的朋友?*我正在使用一个名为 ST_MapAlgebra 的函数。*我的建议是,在拿出那个“散弹枪”之前,先探索其他函数。您的生活会更简单,您的性能会提高 100 倍,您的代码也会更短。
在展示 ST_MapAlgebra 之前,我们将探索其他属于 地图代数 系列且通常比 ST_MapAlgebra 具有更好性能的函数。
30.10.1. 使用 ST_Reclass 重新分类栅格¶
一个经常被忽视的类似地图代数的函数是 ST_Reclass 函数,它在后台等待着人们发现它可以提供的强大功能和速度。
ST_Reclass 做什么?顾名思义,它根据最小范围代数重新分类您的像素值。
让我们重新审视一下我们的纽约市 DEM。也许我们只关心将高程分类为 1) 低,2) 中,3) 高,以及 4) 非常高。我们不需要 411 个值,我们只需要 4 个。有了这个,让我们进行一些重新分类。
分类方案由 reclass 表达式控制。
WITH r AS ( SELECT ST_Union(newrast) As rast
FROM nyc_dem_26918 AS r
INNER JOIN ST_Buffer(ST_Point(586598, 4504816, 26918), 1000 ) AS g(geom)
ON ST_Intersects( r.rast, g.geom )
CROSS JOIN ST_Reclass( ST_Clip(r.rast,g.geom), 1,
'[0-10):1, [10-50):2, [50-100):3,[100-:4','4BUI',0) AS newrast
)
SELECT SUM(ST_Area(gv.geom)::numeric(10,2)) AS area, gv.val
FROM r, ST_DumpAsPolygons(rast) AS gv
GROUP BY gv.val
ORDER BY gv.val;
输出为:
area | val
------------+-----
6754.04 | 1
1753117.51 | 2
1355232.37 | 3
1848.75 | 4
(4 rows)
如果这是我们首选的分类方案,我们可以使用 ST_Reclass 创建一个新表来重新计算每个图块。
30.10.2. 使用 ST_ColorMap 为栅格着色¶
ST_ColorMap 函数是另一个类似地图代数的函数,它可以重新分类您的像素值。但它是波段创建的。它将单个波段栅格(例如我们的 DEM)转换为视觉上可呈现的 3 或 4 波段栅格。
如果您不想费心创建一个,可以使用如下所示的内置颜色图之一:
SELECT ST_ColorMap( ST_Union(newrast), 'bluered') As rast
FROM nyc_dem_26918 AS r
INNER JOIN
ST_Buffer(
ST_Point(586598, 4504816, 26918), 1000
) AS g(geom)
ON ST_Intersects( r.rast, g.geom)
CROSS JOIN ST_Clip(rast, g.geom) AS newrast;
看起来像:

颜色越蓝,高程越低;颜色越红,高程越高。
